The Trillion-Dollar Inefficiency Problem
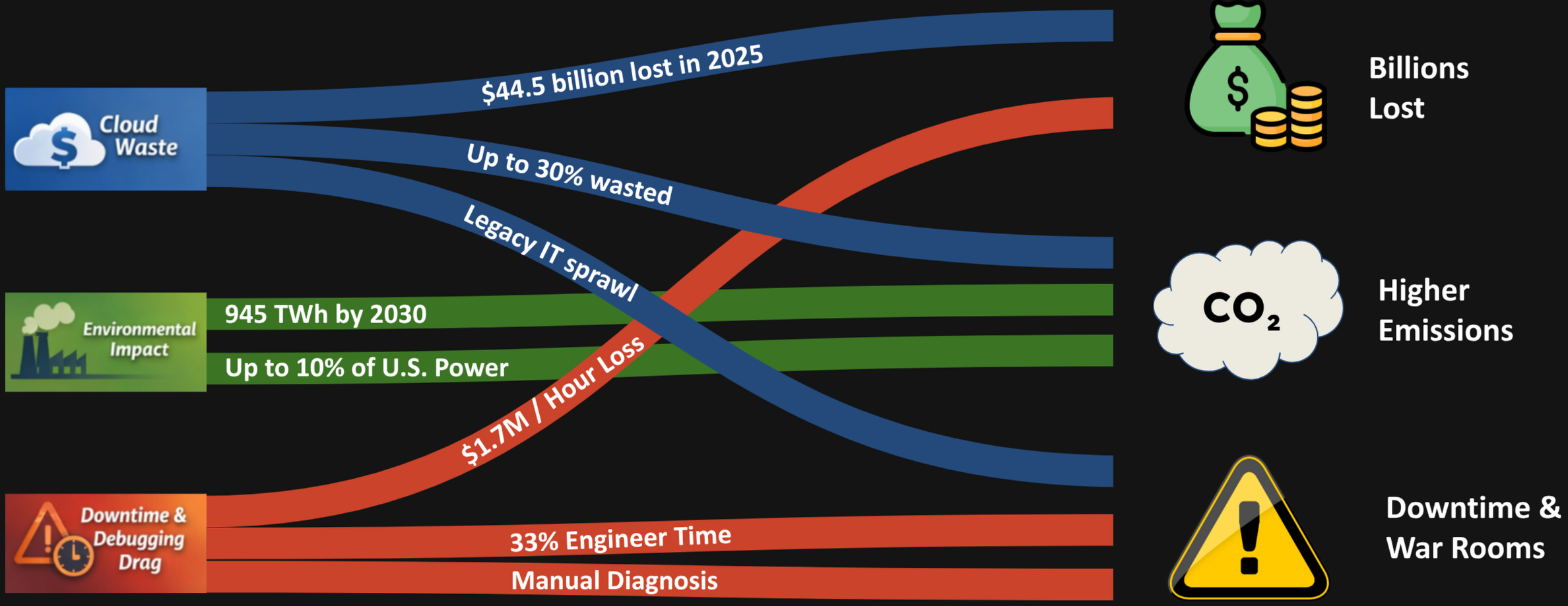
Modern enterprises run on cloud infrastructure, yet an alarming share of that spending delivers no value. According to BCG[1], up to 30% of cloud spending is wasted due to inefficiencies and poor visibility into actual resource utilisation. The scale is staggering: the Harness State of Cloud Cost Report[2] estimates that enterprises will collectively waste approximately $44.5 billion in 2025 from under-utilised infrastructure alone. Meanwhile, TechMonitor/Stacklet[3] finds that 78% of companies estimate 21–50% of their cloud expenditure is wasted annually—money that flows directly to idle VMs, over-provisioned databases, and orphaned storage volumes that nobody remembers creating.
The problem extends beyond cloud line items. Legacy hardware and IT sprawl create hidden costs—energy consumption for cooling servers that run at 10% capacity, maintenance contracts on equipment that should have been decommissioned years ago, and cumulative downtime from aging systems that fail unpredictably. Without a way to trace these inefficiencies to their root causes, organisations keep paying for waste they cannot see.
The Environmental Toll of Inefficient Systems
The consequences are not purely financial. Global data centres consumed approximately 415 TWh of electricity in 2024—roughly 1.5% of worldwide electricity use—and the International Energy Agency[4] projects that figure could reach 945 TWh by 2030 as AI workloads and digital services continue to expand. In the United States alone, data centres already account for 4.4% of national electricity consumption, a share the Department of Energy[5] warns could rise to 6.7–12% by 2028.
Every inefficient system contributes to this trajectory: wasted compute cycles mean wasted energy, unnecessary cooling load, and an inflated carbon footprint. When a memory leak forces a service to run on twice the instances it actually needs, the environmental cost doubles alongside the cloud bill. Identifying and eliminating the source of resource waste reduces emissions at the same time as it reduces cost.
Downtime and the Debugging Drag
When something breaks, the costs escalate rapidly. According to a New Relic survey[6], high-impact IT outages cost an average of $1.7 million per hour. Yet the time to resolve these incidents remains stubbornly long, in large part because the debugging process itself is so inefficient. The same survey reports that engineers spend roughly 31% of their time addressing disruptions—time diverted from feature development, technical-debt reduction, and the strategic work that actually moves the product forward.
The organisational impact compounds from there. Splunk’s State of Observability report[7] reveals that 20% of organisations often or always pull many teams into war rooms during major incidents, while 43% of respondents say they spend too much time simply responding to alerts rather than investigating root causes. The war-room pattern is particularly destructive: it pulls senior engineers away from high-value work, creates cross-team coordination overhead, and often devolves into finger-pointing sessions where each team defends its own service boundaries rather than collaborating on a system-wide diagnosis.
Common outage culprits—network failures, software deployments, environment configuration changes—are rarely isolated events. A single misconfigured load-balancer rule can cascade through service meshes, trigger retry storms, exhaust connection pools, and ultimately surface as a database timeout three hops away from the original fault. Tracing that chain manually, across disparate logging systems and monitoring dashboards, is what stretches incident resolution from minutes to hours.
Industry Statistics: Cloud Waste, Downtime & Debugging
What Can Be Done?
These problems share a common thread: lack of visibility into root causes. Cloud resources stay over-provisioned because nobody can trace the waste to its source. Outages drag on because engineers spend hours correlating symptoms across dashboards instead of pinpointing the fault. Energy consumption grows unchecked because inefficient systems are invisible until the bill arrives.
DeepXplore tackles each layer of this inefficiency crisis with a suite of capabilities purpose-built for continuous, AI-driven performance intelligence.
Pinpoint Root Causes in Seconds, Not Hours
The single biggest lever against waste and downtime is understanding why something went wrong. DeepXplore’s AI-Powered Root Cause Analysis automatically correlates telemetry, deployment events, and configuration changes to surface the most likely causes of any anomaly—eliminating war rooms and reducing mean time to resolution from hours to minutes.
Catch Degradation Before It Becomes an Outage
Slow leaks, gradual performance decay, and creeping resource consumption are invisible to periodic testing. DeepXplore’s 24/7 Testing with Advanced Analytics runs continuous baseline traffic against your systems, building dense historical data that reveals trends days before they breach SLAs. Instead of discovering a memory leak after the next outage, your team sees the trajectory and acts preventively.
Validate Infrastructure Under Realistic Load
Flat-rate load tests do not expose the autoscaler bugs, connection-pool exhaustion, and cold-start latency spikes that appear under real traffic patterns. With Realistic Traffic Simulation, DeepXplore models peak hours, off-peak lulls, and the transitions between them—so your infrastructure is validated against the same patterns it will face in production, not an artificial constant rate.
Test Complete User Journeys, Not Isolated Endpoints
An endpoint that passes in isolation can fail as part of a multi-step workflow. DeepXplore’s User Journey Testing chains API requests into full stateful journeys—login, browse, add to cart, checkout, payment—with automatic data extraction between steps. This turns isolated endpoint checks into true system-level validation that mirrors how real customers use your product.
Eliminate Compliance Bottlenecks with Synthetic Data
Regulated industries lose weeks waiting for anonymised test data that is either stale or statistically meaningless. DeepXplore’s Synthetic Data Generation produces near-realistic data that satisfies GDPR and other regulatory constraints while covering edge cases like sanction-list matches and regional name distributions. Testing with realistic data uncovers the bugs that random data never will—without the compliance risk of using production datasets.
Close the Loop with Automated Fixes
Knowing the root cause is only half the battle. DeepXplore Code picks up where root cause analysis ends—it understands your codebase, implements the fix, runs tests, and deploys the change automatically. No context-switching, no war rooms, no waiting for the right engineer to become available. The gap between diagnosis and resolution shrinks from hours to minutes.
Together, these capabilities form a closed loop: continuous testing detects problems early, realistic traffic and journey simulation prevents them from reaching production, synthetic data removes compliance blockers, AI-powered root cause analysis identifies what went wrong, and DeepXplore Code fixes it automatically. The result is less waste, less downtime, and engineering teams focused on building product instead of fighting fires.